 |
|
Reliability and
Validity
Chong
Ho Yu, Ph.D.s |
Conventional views of reliability
(AERA et al., 1985)
-
Temporal
stability: This type of reliability utilizes the same form of a test on two or
more separate occasions to the same group of examinees
(Test-retest). On many occasions this approach is not practical
because the behaviors of the examinees could be affected by repeated measurements.
For example, the examinees might be adaptive to the test format and
thus tend to score higher in later tests. This consequence is known
as the carry-over effect. Hence, careful implementation of the
test-retest approach is strongly recommended (Yu, 2005).
-
Form
equivalence: This approach requires two different test
forms based on the same content (Alternate form). After alternate forms have been
developed and validated by test equating, it can be used for different examinees.
In high-stake examinations it is very common to employ this method
to preempt cheating. Because the two forms have different items, an
examinee who took Form A earlier could not "help" another student
who takes Form B later.
-
Internal
consistency: This type of reliability estimate uses the coefficient of test scores
obtained from a single test or survey (Cronbach
Alpha, KR20, Spilt-half). Consider this scenario: respondents are asked to rate
the statements in an attitude
survey about computer anxiety. One statement is: "I feel
very negative about computers in general." Another
statement is: "I enjoy using computers." People who
strongly agree with the first statement should be
strongly disagree with the second statement, and vice
versa. If the rating of both statements is high or low
among several respondents, the responses are said to be
inconsistent and patternless. The same principle can be
applied to a test. When no pattern is found in the
students' responses, probably the test is too difficult
and as a result the examinees just guess the answers randomly.
-
Inter-rater reliability:
This is a measure of agreement between two raters, coders, or
observers. It is also known as intercoder reliability. This reliability
estimate is useful when the subject matter under judgment is highly
subjective (e.g. aesthetical value of a painting or a photo). If the
rating scale is continuous (e.g. 0-10), Pearson's product moment
correlation coefficient is suitable. If the scale is ordinal in nature,
Spearman's coefficient is the most appropriate approach. For
categorical classification (e.g. pass/fail), Cohen's Kappa coefficient should be employed.

-
Reliability is a necessary but not
sufficient condition for validity. For instance,
if the needle of the scale is five pounds away from zero,
I always over-report my weight by five pounds. Is the
measurement consistent? Yes, but it is consistently
wrong! Is the measurement valid? No! (But if it always under-reports
my weight by five pounds, I will accept this measurement!)
-
Performance,
portfolio, and responsive evaluations, where the tasks vary
substantially from student to student and where multiple tasks may be
evaluated simultaneously, are attacked for lacking reliability. One of
the difficulties is that there are more than one source of measurement
errors in performance assessment. For example, the reliability of
writing skill test score is affected by the raters, the mode of
discourse, and several other factors (Parkes, 2000).
-
Replications as unification: Users may
be confused by the diversity of reliability indices. Nevertheless, different
types of reliability measures share a common thread: What constitutes a
replication of a measurement procedure? (Brennan, 2001) Take internal
consistency as an example. This measure is used because it is convenient to
compute the reliability index based upon data collected from one occasion.
However, the ultimate inference should go beyond one single testing occasion to
others (Yu, 2005). In other words, any procedures for estimating reliability
should attempt to mirror a result based upon full-length replications.
Conventional views of validity
(Cronbach, 1971)
-
Face
validity: Face validity simply means that the
validity is taken at face value. As a check on face validity,
test/survey items are sent to teachers or other subject matter
experts to obtain
suggestions for modification. Because of its vagueness
and subjectivity, psychometricians have abandoned this
concept for a long time. However, outside the measurement
arena, face validity has come back in another form. While
discussing the validity of a theory, Lacity and Jansen
(1994) defines validity as making common sense, and
being persuasive and seeming right to the reader. For
Polkinghorne (1988), validity of a theory refers to
results that have the appearance of truth or reality.
The internal structure of things may not concur with
the appearance. Many times professional knowledge is
counter-common sense. The criteria of validity in
research should go beyond "face," "appearance," and
"common sense."
-
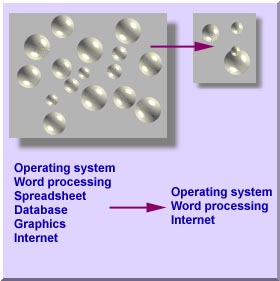 Content
validity: In the context of content validity, we draw an inference from
the test scores
to a larger domain of items similar to those on the test.
Thus, content validity is concerned with sample-population
representativeness. i.e. the knowledge and skills
covered by the test items should be representative to the
larger domain of knowledge and skills. Content
validity: In the context of content validity, we draw an inference from
the test scores
to a larger domain of items similar to those on the test.
Thus, content validity is concerned with sample-population
representativeness. i.e. the knowledge and skills
covered by the test items should be representative to the
larger domain of knowledge and skills.
For example, computer literacy includes skills in
operating system, word processing, spreadsheet, database,
graphics, internet, and many others. However, it is
difficult, if not impossible, to administer a test
covering all aspects of computing. Therefore, only
several tasks are sampled from the universe of computer
skills.
Content validity is usually established by content
experts. Take computer literacy as an example again.
A test of computer literacy should be written or reviewed
by computer science professors because it is assumed that
computer scientists should know what are important in his
own discipline. At first glance, this approach looks
similar to the validation process of face validity, but
yet there is a subtle difference. In content validity, evidence is
obtained by looking for agreement in judgments by judges. In short,
face validity can be established by one person but content validity
should be checked by a panel, and thus usually it goes hand in hand
with inter-rater reliability.
However, this approach has some drawbacks. Usually
experts tend to take their knowledge for granted and
forget how little other people know. It is not uncommon
that some tests written by content experts are extremely
difficult.
Second,
very often content experts fail to identify the learning objectives of
a subject. Take the following question in a philosophy test as an
example:
-
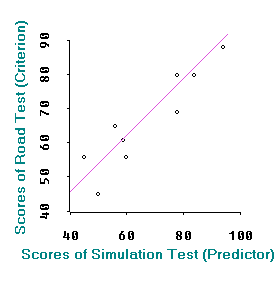 Criterion:
When the focus of the test is on criterion validity, we draw an
inference from test scores to performance. A high score of a valid
test indicates that the test taker has met
the performance criteria. Criterion:
When the focus of the test is on criterion validity, we draw an
inference from test scores to performance. A high score of a valid
test indicates that the test taker has met
the performance criteria.
Regression analysis can be applied to establish
criterion validity. An independent variable could be used
as a predictor variable and a dependent variable,
the criterion variable. The correlation
coefficient between them is called validity
coefficients.
For instance, the test scores of the driving test by simulation
is considered the predictor variable while the scores of the road test
is treated as the criterion variable. It is hypothesized that if the
tester passes the simulation test, he/she should be a competent driver. In other words, if the
simulation test scores could predict the road test scores
in a regression model, the simulation test is claimed to
have a high degree of criterion validity.
In short, criterion validity is about
prediction rather than explanation.
Predication is concerned with non-casual or mathematical
dependence where as explanation is pertaining to causal
or logical dependence. For example, one can predict the
weather based on the height of mercury inside a
thermometer. Thus, the height of mercury could satisfy
the criterion validity as a predictor. However, one
cannot explain why the weather changes by the variation of
mercury height. Because of this limitation of criterion
validity, an evaluator has to conduct construct
validation.
-
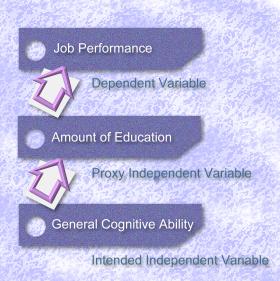 Construct:
When construct validity is emphasized, as the name implies, we draw
an inference form test scores to a psychological
construct. Because it is concerned with abstract and
theoretical construct, construct validity is also known
as theoretical construct. Construct:
When construct validity is emphasized, as the name implies, we draw
an inference form test scores to a psychological
construct. Because it is concerned with abstract and
theoretical construct, construct validity is also known
as theoretical construct.
According to Hunter and Schmidt (1990), construct
validity is a quantitative question rather than a
qualitative distinction such as "valid" or "invalid"; it
is a matter of degree. Construct validity can be measured
by the correlation between the intended
independent variable (construct) and the proxy
independent variable (indicator, sign) that is actually
used.
For example, an evaluator wants to study the
relationship between general cognitive ability and job
performance. However, the evaluator may not be able to
administer a cognitive test to every subject. In this
case, he can use a proxy variable such as "amount of
education" as an indirect indicator of cognitive ability.
After he administered a cognitive test to a portion of
all subjects and found a strong correlation between
general cognitive ability and years of schooling, the
latter can be used to the larger group because its
construct validity is established.
Other authors (e.g. Angoff,1988; Cronbach & Quirk,
1976) argue that construct validity cannot be expressed
in a single coefficient; there is no mathematical index
of construct validity. Rather the nature of construct
validity is qualitative.
There are two types of indictors:
When an indictor is expressed in terms of multiple
items of an instrument, factor analysis is utilized
for construct validation.
Test bias is a major threat against construct
validity, and therefore test bias analyses should be
employed to examine the test items (Osterlind, 1983). The presence of test bias definitely affects the
measurement of the psychological construct. However, the
absence of test bias does not guarantee that the test
possesses construct validity. In other words, the absence
of test bias is a necessary, but not a sufficient
condition.
-
Construct validation as unification:
The criterion and the content models tends to be empirical-oriented
while the construct model is inclined to be theoretical. Nevertheless,
all models of validity requires some form of interpretation: What is
the test measuring? Can it measure what it intends to measure? In
standard scientific inquiries, it is important to explicitly formulate
an interpretative (theoretical) framework and then to subject it to
empirical challenges. In this sense, theoretical construct validation
is considered functioning as a unified framework for validity (Kane,
2001).
A modified view of reliability
(Moss, 1994)
-
"There can be validity without reliability if reliability is defined as consistency
among independent measures.
-
Reliability is an aspect of construct validity. As
assessment becomes less standardized, distinctions
between reliability and validity blur.
-
In many situations such as searching faculty
candidate and conferring graduate degree, committee
members are not trained to agree on a common set of
criteria and standards
-
Inconsistency in students' performance across tasks
does not invalidate the assessment. Rather it becomes an
empirical puzzle to be solved by searching for a more
comprehensive interpretation.
-
Initial disagreement (e.g., among students, teachers,
and parents in responsive evaluation) would not
invalidate the assessment. Rather it would provide an
impetus for dialog."
Li (2003) argued that the preceding view is incorrect:
-
"The
definition of reliability should be defined in terms of the classical
test theory: the squared correlation between observed and true scores
or the proportion of true variance in obtained test scores. -
Reliability is a unitless measure and thus it is already model-free
or standard-free.
-
It
has been a tradition that multiple factors are introduced into a test
to improve validity but decrease internal-consistent reliability."
An extended view of Moss's reliability
(Mislevy, 2004)
-
Being inspired by Moss, Mislevy went further to ask whether there can be reliability without reliability (indices).
-
By
blending psychometrics and Hermeneutics, in which a holistic and
integrative approach to understand the whole in light of its parts is
used (the whole is more than the summation of its parts), Mislevy
demanded psychometricians to think about what they intend to make
inferences about. -
In many situations we don't present just one
single argument; rather problem solving involves a chain
of arguments with multiple evidence.
-
Off-the-shelf inferential
technology (e.g. compute reliability indices) may be
problematic if we measure things or tasks that we don't know much about.
-
Probability-based reasoning to complex assessments based upon cognitive
science is necessary.
A radical view of reliability
(Thompson et al, 2003)
-
Reliability is not a property of the test; rather it is attached
to the property of the data. Thus, psychomterics is datammetrics.
-
Tests are not reliable. It is important to explore reliability
in virtually all studies.
-
Reliability generalization,
which is similar to meta-analysis, should
be implemented to assess variance of measurement error across
many studies.
An updated perspective of reliability
(Cronbach, 2004)
In a 2004's article, Lee Cronbach, the inventor of Cronbach Alpha as
a way of measuring reliability, reviewed the historical development of
Cronbach Alpha. He asserted, "I no longer regard the formula (of
Cronbach Alpha) as the most appropriate way to examine most data. Over
the years, my associates and I developed the complex generaliability
(G) theory" (p. 403). Discussion of the G theory is beyond the scope of
this document. Nevertheless, Cronbach did not object use of Cronbach
Alpha but he recommended that researchers should take the following
into consideration while employing this approach:
-
Standard error of measurement:
It is the most important piece of information to report regarding
the instrument, not a coefficient.
-
Independence of sampling
-
Heterogeneity of content
-
How the measurement will be used:
Decide whether future uses of the instrument are likely to be
exclusively for absolute decisions, for differential decisions, or
both.
-
Number of conditions for the test
A critical view of validity
(Pedhazur & Schmelkin,1991)
-
"Content validity is not a type of validity at all
because validity refers to inferences made about scores,
not to an assessment of the content of an
instrument.
-
The very definition of a construct implies a domain
of content. There is no sharp distinction between test
content and test construct."
A modified view of validity
(Messick, 1995)
The conventional view (content, criterion, construct) is
fragmented because it fails to
take into account both evidence of the value implications of
score meaning as a basis for actionable items and the social
consequences of using the test scores.
Validity is not a property of the test or
assessment, but rather it is about the meaning of the test
scores.
-
Content: evidence
of content relevance, representativeness, and technical
quality
-
Substantive: theoretical
rationale
-
Structural: the
fidelity of the scoring structure
-
Generalizability: generalization
to the population and across populations
-
External: applications
to multitrait-multimethod comparison
-
Consequential: bias,
fairness, and justice; the social consequence of the
assessment to the society
Critics
argued that consequences should not be a component of validity because
test developers should not be held responsible for the consequences of
misuse that are out of their control. Rather, accountability should be
tied to the misuser. Messick (1998) counter-argued that social
consequences of score interpretation include the value implications of the construct,
and this implication must be addressed by evaluating the meaning of the
test score. While test developers should not be accountable to misuse of tests, they should still
be cautious to the unanticipated consequences of legitimate score interpretation.
A different view of reliability
and validity (Salvucci, Walter, Conley, Fink, & Saba
(1997)
Some scholars argue that the traditional view that
"reliability is a necessary but not a sufficient condition
of validity" is incorrect. This school of thought
conceptualizes reliability as invariance and validity
as unbiasedness. A sample statistic may have an
expected value over samples equal to the population
parameter (unbiasedness), but have very high variance from a
small sample size. Conversely, a sample statistic can have
very low sampling variance but have an expected value far
departed from the population parameter (high bias). In this
view, a measure can be unreliable (high variance) but still
valid (unbiased).
|
|
|
|
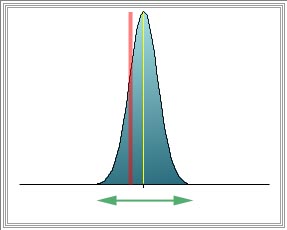
Population parameter (Red line) = Sample statistic (Yellow line) --> unbiased
High variance (Green line)
Unreliable but valid |
Population parameter (Red line) <> Sample statistic (Yellow line) --> Biased
low variance (Green line)
Invalid but reliable |
Caution and advice
There is a common misconception that if someone adopts a
validated instrument, he/she does not need to check the
reliability and validity with his/her own data. Imagine
this: When I buy a drug that has been approved by FDA and my
friend asks me whether it heals me, I tell him, "I am taking
a drug approved by FDA and therefore I don't need to know
whether it works for me or not!" A responsible evaluator
should still check the instrument's reliability and validity
with his/her own data and make any modifications if
necessary.
Low reliability is less detrimental to the performance
pretest. In the pretest where subjects are not exposed to
the treatment and thus are unfamiliar with the subject
matter, a low reliability caused by random guessing is
expected. One easy way to overcome this problem is to
include "I don't know" in multiple choices. In an
experimental settings where students' responses would not
affect their final grades, the experimenter should
explicitly instruct students to choose "I don't know"
instead of making a guess if they really don't know the
answer. Low reliability is a signal of high measurement
error, which reflects a gap between what students actually
know and what scores they receive. The choice "I don't know"
can help in closing this gap.
Last Updated: 2012
References
American Educational Research Association, American
Psychological Association, & National Council on
Measurement in Education. (1985). Standards for
educational and psychological testing. Washington, DC:
Authors.
Angoff, W. H. (1988). Validity: An evolving concept. In
H. Wainer & H. I. Braun (Eds.), Test validity.
Hillsdale, NJ: Lawrence Erlbaum.
Brennan, R. (2001). An essay on the history and future of reliability from the perspective of replications.
Journal of Educational Measurement, 38, 295-317.
Cronbach, L. J. (1971). Test validation. In R. L.
Thorndike (Ed.). Educational Measurement (2nd Ed.).
Washington, D. C.: American Council on Education.
Cronbach, L. J. (2004). My current thoughts on Coefficient Alpha and
successor procedures. Educational and Psychological Measurement, 64,
391-418.
Cronbach, L. J. & Quirk, T. J. (1976). Test validity.
In International Encyclopedia of Education. New York:
McGraw-Hill.
Goodenough, F. L. (1949). Mental testing: Its history,
principles, and applications. New York: Rinehart.
Hunter, J. E.; & Schmidt, F. L. (1990). Methods of
meta-analysis: Correcting error and bias in research
findings. Newsbury Park: Sage Publications.
Kane, M. (2001). Current concerns in validity theory. Journal of educational Measurement, 38, 319-342.
Lacity, M.; & Jansen, M. A. (1994). Understanding
qualitative data: A framework of text analysis methods.
Journal of Management Information System, 11,
137-160.
Li, H. (2003). The resolution of some paradoxes related to
reliability and validity. Journal of Educational and Behavioral
Statistics, 28, 89-95.
Messick, S. (1995). Validity of psychological assessment:
Validation of inferences from persons' responses and
performance as scientific inquiry into scoring meaning.
American Psychologist, 9, 741-749.
Messick, S. (1998). Test validity: A matter of consequence. Social Indicators Research, 45, 35-44.
Mislevy, R. (2004). Can there be reliability without reliability? Journal of Educational and Behavioral Statistics, 29, 241-244.
Moss, P. A. (1994). Can there be validity without
reliability? Educational Researcher, 23, 5-12.
Osterlind, S. J. (1983). Test item bias. Newbury
Park: Sage Publications.
Parkes, J. (2000). The relationship between the reliability and cost of performance assessments. Education Policy Analysis Archives, 8.
Retrieved from http://epaa.asu.edu/epaa/v8n16/
Pedhazur, E. J.; & Schmelkin, L. P. (1991).
Measurement, design, and analysis: An integrated
approach. Hillsdale, NJ: Lawrence Erlbaum Associates,
Publishers.
Polkinghorne, D. E. (1988). Narrative knowing and the
human sciences. Albany: State University of New York
Press.
Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba,
M. (1997). Measurement error studies at the National
Center for Education Statistics. Washington D. C.: U. S.
Department of Education
Thompson, B. (Ed.) (2003). Score reliability: Contemporary
thinking on reliability issues. Thousand Oaks: Sage.
Yu, C. H. (2005). Test-retest reliability. In K. Kempf-Leonard (Ed.). Encyclopedia of Social Measurement, Vol. 3 (pp. 777-784). San
Diego, CA: Academic Press.
Questions for
discussion
Pick one of the following cases and determine whether the
test or the assessment is valid. Apply the concepts of
reliability and validity to the situation. These cases may
be remote to this cultural context. You may use your own
example.
-
In ancient China, candidates for government officials
had to take the examination regarding literature and
moral philosophy, rather than public administration.
-
Before July 1, 1997 when Hong Kong was a British
colony, Hong Kong doctors, including specialists, who
graduated from non-Common Wealth medical schools had to
take a general medical examination covering all general
areas in order to be certified.
Navigation
Contact
|